首先吐槽:Markdown太难用了,折磨死人,不会而且显示效果还没我的笔记好。

grep: Global search Regular Expression(RE) and Print out the line
作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检查;打印匹配到的行
模式:由正则表达式字符及文本字符所编写的过滤条件
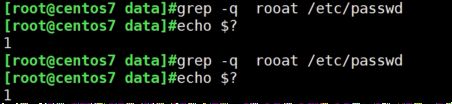
grep -q的用法
正则表达式也叫规则表达式
REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,
其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能
支持程序:grep、sed、awk、vim、less、nginx、varnish
分两类 {1.基本正则表达式BRE 2.扩展正则表达式ERE}
元字符分类:字符匹配、匹配字数、位置锚定分组
匹配字符
[] 匹配指定范围内的任意单个字符,示例:[wang] [0-9]
. 匹配任意单个字符
匹配字数
** 匹配前面的字符任意次,包括0次
.:功能相当于通配符里的*,也即匹配任意个数的任意字符
? 匹配其前面的字符0或1次
+ 匹配其前面的字符至少1次
{n} 匹配前面的字符n次
{m,n} 匹配前面的字符至少m次,至多n次
{,n} 匹配前面的字符至多n次
{n,} 匹配前面的字符至少n次
位置锚定*
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]$ 空白行
&; 或 b 词首锚定,用于单词模式的左侧
&; 或 b 词尾锚定,用于单词模式的右侧
&;PATTERN&; 匹配
b是正则表达式规定的一个特殊代码(好吧,某些人叫它元字符,metacharacter),代表着单词的开头或结尾,也就是单词的分界处。
分组
?分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: 1,2,3,...
1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符;从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身
示例1
b(w+)bs+1b可以用来匹配重复的单词,像go go,或者kitty kitty。这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(b(w+)b),这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符(s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(1)。
示例2